author:skate
time:2013/04/09
总结记录下innodb的索引概念,以备查看
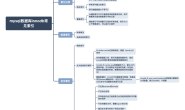
innodb索引分类:
聚簇索引(clustered index)
1) 有主键时,根据主键创建聚簇索引
2) 没有主键时,会用一个唯一且不为空的索引列做为主键,成为此表的聚簇索引
3) 如果以上两个都不满足那innodb自己创建一个虚拟的聚集索引
辅助索引(secondary index)
非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引
myisam索引:因为myisam的索引和数据是分开存储存储的,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索
索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因
innodb索引:innodb的数据和索引放在一起,当找到索引也就找到了数据
自适应哈希索引:innodb会监控表上的索引使用情况,如果观察到建立哈希索引可以带来速度的提升,那就建立哈希索引,自 适应哈希索引通过缓冲池的B+树构造而来,
因此建立的速度很快,不需要将整个表都建哈希索引,InnoDB 存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引。自适应哈希索引不需要
存储磁盘的,当停库内容会丢失,数据库起来会自己创建,慢慢维护索引。
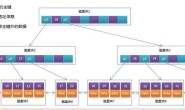
聚簇索引:
MySQL InnoDB一定会建立聚簇索引,把实际数据行和相关的键值保存在一块,这也决定了一个表只能有一个聚簇索引,即MySQL不会一次把数据行保存在二个地方。
1) InnoDB通常根据主键值(primary key)进行聚簇
2) 如果没有创建主键,则会用一个唯一且不为空的索引列做为主键,成为此表的聚簇索引
3) 上面二个条件都不满足,InnoDB会自己创建一个虚拟的聚集索引
优点:
聚簇索引的优点,就是提高数据访问性能。聚簇索引把索引和数据都保存到同一棵B+树数据结构中,并且同时将索引列与相关数据行保存在一起。这意味着,当你访问同一数据页不同行记录时,已经把页加载到了Buffer中,再次访问的时候,会在内存中完成访问,不必访问磁盘。不同于MyISAM引擎,它将索引和数据没有放在一块,放在不同的物理文件中,索引文件是缓存在key_buffer中,索引对应的是磁盘位置,不得不通过磁盘位置访问磁盘数据。
缺点:
1) 维护索引很昂贵,特别是插入新行或者主键被更新导至要分页(page split)的时候。建议在大量插入新行后,选在负载较低的时间段,通过OPTIMIZE TABLE优化表,因为必须被移动的行数据可能造成碎片。使用独享表空间可以弱化碎片
2) 表因为使用UUId作为主键,使数据存储稀疏,这就会出现聚簇索引有可能有比全表扫面更慢,所以建议使用int的auto_increment作为主键
3) 如果主键比较大的话,那辅助索引将会变的更大,因为辅助索引的叶子存储的是主键值;过长的主键值,会导致非叶子节点占用占用更多的物理空间
辅助索引
在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找。辅助索引叶子节点存储的不再是行的物理位置,而是主键值。通过辅助索引首先找到的是主键值,再通过主键值找到数据行的数据叶,再通过数据叶中的Page Directory找到数据行。
复合索引
由多列创建的索引称为符合索引,在符合索引中的前导列必须出现在where条件中,索引才会被使用
ALTER TABLE `test`.`users` ADD INDEX `idx_users_id_name` (`name`(10) ASC, `id` ASC) ;
前缀索引
当索引的字符串列很大时,创建的索引也就变得很大,为了减小索引体积,提高索引的扫描速度,就用索引的前部分字串索引,这样索引占用的空间就会大大减少,并且索引的选择性也不会降低很多。而且是对BLOB和TEXT列进行索引,或者非常长的VARCHAR列,就必须使用前缀索引,因为MySQL不允许索引它们的全部长度。
使用:
列的前缀的长度选择很重要,又要节约索引空间,又要保证前缀索引的选择性要和索引全长度选择性接近。
唯一索引
唯一索引比较好理解,就是索引值必须唯一,这样的索引选择性是最好的
主键索引
主键索引就是唯一索引,不过主键索引是在创建表时就创建了,唯一索引可以随时创建。
说明
主键和唯一索引区别
1) 主键是主键约束+唯一索引
2) 主键一定包含一个唯一索引,但唯一索引不是主键
3) 唯一索引列允许空值,但主键列不允许空值
4) 一个表只能有一个主键,但可以有多个唯一索引
索引扫描方式:
紧凑索引扫描(dense index):
在最初,为了定位数据需要做权表扫描,为了提高扫描速度,把索引键值单独放在独立的数据的数据块里,并且每个键值都有个指向原数据块的指针,因为索引比较小,扫描索引的速度就比扫描全表快,这种需要扫描所有键值的方式就称为紧凑索引扫描
松散索引扫描(sparse index):
为了提高紧凑索引扫描效率,通过把索引排序和查找算法(B+trre),发现只需要和每个数据块的第一行键值匹配,就可以判断下一个数据块的位置或方向,因此有效数据就是每个数据块的第一行数据,如果把每个数据块的第一行数据创建索引,这样在这个新创建的索引上折半查找,数据定位速度将更快。这种索引扫描方式就称为松散索引扫描。
覆盖索引扫描(covering index):
包含所有满足查询需要的数据的索引称为覆盖索引,即利用索引返回select列表中的字段,而不必根据索引再次读取数据文件
索引相关常用命令:
1) 创建主键
CREATE TABLE `pk_tab2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a1` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2) 创建唯一索引
create unique index indexname on tablename(columnname);
alter table tablename add unique index indexname(columnname);
3) 创建单列一般索引
create index indexname on tablename(columnname);
alter table tablename add index indexname(columnname);
4) 创建单列前缀索引
create index indexname on tablename(columnname(10)); //单列的前10个字符创建前缀索引
alter table tablename add index indexname(columnname(10)); //单列的前10个字符创建前缀索引
5) 创建复合索引
create index indexname on tablename(columnname1,columnname2); //多列的复合索引
create index indexname on tablename(columnname1,columnname2(10)); //多列的包含前缀的复合索引
alter table tablename add index indexname(columnname1,columnname2); //多列的复合索引
alter table tablename add index indexname(columnname1,columnname(10)); //多列的包含前缀的复合索引
6) 删除索引
drop index indexname on tablename;;
alter table tablename drop index indexname;
7) 查看索引
show index from tablename;
show create table pk_tab2;
——–end——–

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~转载请注明:苏demo的别样人生 » innodb索引概念


 Arabic
Arabic Chinese (Simplified)
Chinese (Simplified) Dutch
Dutch English
English French
French German
German Italian
Italian Portuguese
Portuguese Russian
Russian Spanish
Spanish